

Chair of Data Science and Data Engineering
 Prof. Dr. Emmanuel Müller
Prof. Dr. Emmanuel Müller
Chair of Data Science and Data Engineering
Department of Computer Science
Technical University of Dortmund
Principal Investigator LAMARR Institute
for Machine Learning and Artificial Intelligence
Founding Director RC-Trust.AI
Research Center Trustworthy Data Science and Security
E-Mail:
emmanuel.mueller(at)cs.tu-dortmund.de
Otto-Hahn-Straße 14
Campus Nord
D-44227 Dortmund
Research and Teaching Overview
Our research covers data mining, machine learning, scalable algorithms, and interactive exploration for high dimensional data, complex graphs, time series, and data streams. The chair is leading and contributing to several open-source initiatives enabling repeatability and comparability for the research community. We have organized several tutorials and workshops at major data mining, database, and machine learning conferences, and edited a special issue for the Machine Learning Journal. In the past few years, we have initiated and coordinated various education programmes for “Data Science” and “Data Engineering”: One on the level of university education (M.Sc. programme), two graduate schools (PhD programmes) and multiple executive education programmes for industry.
Research Activities
Knowledge Discovery and Data Mining
Knowledge discovery and data mining, as part of many scientific and industrial applications, does not end with the execution of algorithms. With data mining algorithms, resulting in the discovery of unknown, novel, and unexpected patterns, one should aim at assisting humans in their daily decision making. On the one side, we investigate efficient algorithms, which scale with size and complexity of the data. Moreover, on the other side, our algorithms generate verifiable and explainable knowledge for human users.
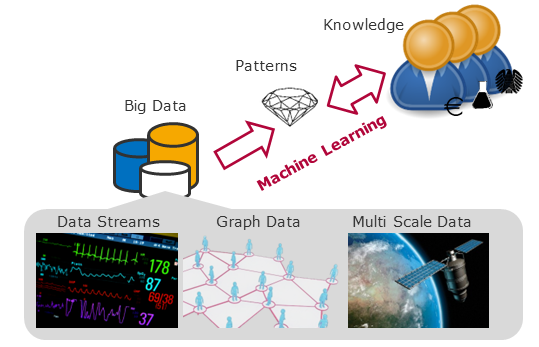 Algorithms for Big Data Analytics
Algorithms for Big Data Analytics
Our research addresses theoretic challenges in correlation analysis, representation learning, (un-)supervised feature selection, cluster and outlier detection as well as practical challenges in efficient computation of these models in large and complex datasets. The development of novel techniques for complex data spaces (e.g. graph structures, time series, data streams, or high dimensional data) is a particular challenge in this area. We overcome information loss and scalability challenges of traditional data mining techniques that assume homogeneous data and enable big data analytics on heterogeneous datasets. Our chair investigates algorithms for the selection of relevant attributes in high dimensional data, correlations in time series data, change in multivariate data streams, and similarity structures in graph data.
Verifiable Knowledge Discovery for Human Users
Our research aims at an easy to understand presentation of data analytics results. We represent intrinsic dependencies between different information sources for human users. Our research includes exploring the automatic extraction of dependencies and pattern descriptions, which is a significant research contribution for many applications where patterns have to be verified by the users. Human users require such descriptions of potential reasons for each of the detected patterns. Hence, we have proposed verifiable descriptions for learned representations, unexpected patterns, user-driven data exploration, and explainable data profiling.
Teaching Activities
 Data Science Education
Data Science Education
In our lectures, we cover fundamental concepts in the field of Big Data Analytics for students in B.Sc./M.Sc. Computer Science and B.Sc./M.Sc. Data Science programmes. Techniques for the analysis of large and complex datasets have a significant impact in many industrial and scientific applications. In science, industry, and society, in general, there is the necessity of understanding complex data by extracting valuable patterns from a multitude of datasets. In our courses, we introduce the systematic processing of large data volumes as a precondition for both human data understanding and automatic data analysis. We teach fundamental data analytics techniques applicable to different domains in science and industry.
Lectures, Labs, and Seminars
We provide basic lectures, lab courses, and practice-oriented projects as introductory courses:
- Big Data Analytics (every winter term)
- Fundamentals in Statistics and Linear Algebra
- Fundamentals in Data Structures and Scalable Algorithms
- Big Data Analytics Lab (every summer term) (incl. annual Data-Mining-Cup competition)
- Projects on selected machine learning topics (e.g. “Predictive Diagnostics”, “Graph Exploration”, …)
We provide a selected set of advanced lectures and research seminars for specialization in data science and engineering:
- Machine Learning for Sequential Data and Graph Data
- Machine Learning Paradigms for Complex Data
- Graph Mining and Exploration
- Indexing Structures for Efficient Database Access
- Data Science Challenges in Practice
- Smart Representations for Big Data Analytics
- Data Science Research Labs (e.g. “Exploration of Complex Networks”, “Representation Learning for Predictive Maintenance”, …)
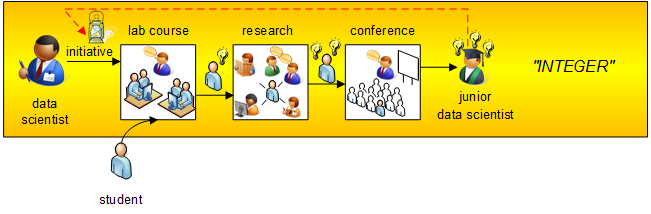
INTEGER Teaching Concept
In our Data Science and Data Engineering Labs, we supervise students w.r.t. open research challenges. Courses reflect our research focus on formal problem settings and scalable algorithmic solutions. As result of these lab courses we aim at publication and presentation of results at international conferences, i.e. students will participate in the entire research process! We have named this course style “INTEGER”. INTEGER provides students the opportunity to participate in research. As part of lab courses, we supervise Bachelor and Master students w.r.t. open research challenges, development of novel solutions, publication of results, and let the student’s present their work at international conferences. With INTEGER students have successfully participated in the entire research process and gained enthusiasm for research.
Selected Publications
All of our publications are listed online [DBLP Bibliography] – [ACM Digital Library] – [Google Scholar]
-
Magdalena Wischnewski, Nicole Krämer, Emmanuel Müller:
Measuring and Understanding Trust Calibrations for Automated Systems: A Survey of the State-Of-The-Art and Future Directions
Proc. ACM Conference on Human Factors in Computing Systems (CHI 2023) [Full Text PDF][Talk at CHI 2023] -
Benedikt Böing, Simon Klüttermann, Emmanuel Müller:
Post-Robustifying Deep Anomaly Detection Ensembles by Model Selection
Proc. IEEE 22nd International Conference on Data Mining (ICDM 2022) [Full Text PDF] - Chiara Balestra, Florian Huber, Andreas Mayr, Emmanuel Müller:
Unsupervised Features Ranking via Coalitional Game Theory for Categorical Data
(Best Paper Award) Proc. 24th International Conference on Big Data Analytics and Knowledge Discovery [Full Text PDF] - Carina Newen, Emmanuel Müller:
Unsupervised DeepView: Global Explainability of Uncertainties for High Dimensional Data
Proc. IEEE International Conference on Knowledge Graph (ICKG 2022) [Full Text PDF] -
Erik Scharwächter, Jonathan Lennartz, Emmanuel Müller:
Differentiable Segmentation of Sequences
Proc. International Conference on Learning Representations (ICLR 2021) [Full Text PDF] -
Anton Tsitsulin, Marina Munkhoeva, Davide Mottin, Panagiotis Karras, Ivan Oseledets, Emmanuel Müller:
FREDE: Anytime Graph Embeddings
Proc. International Conference on Very Large Data Bases (VLDB 2021) [Full Text PDF] -
Benedikt Böing, Rajarshi Roy, Emmanuel Müller, Daniel Neider:
Quality Guarantees for Autoencoders via Unsupervised Adversarial Attacks
Proc. European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD 2020) [Full Text PDF] -
Erik Scharwächter, Emmanuel Müller:
Two-Sample Testing for Event Impacts in Time Series
Proc. SIAM International Conference on Data Mining (SDM 2020) [Full Text PDF] -
Lukas Ruff, Robert A. Vandermeulen, Nico Görnitz, Alexander Binder, Emmanuel Müller, Klaus-Robert Müller, Marius Kloft:
Deep Semi-Supervised Anomaly Detection
Proc. International Conference on Learning Representations (ICLR 2020) [Full Text PDF] -
Anton Tsitsulin, Marina Munkhoeva, Davide Mottin, Panagiotis Karras, Alex Bronstein, Ivan Oseledets, Emmanuel Müller:
The Shape of Data: Intrinsic Distance for Data Distributions
Proc. International Conference on Learning Representations (ICLR 2020) [Full Text PDF] -
Nikita Klyuchnikov, Davide Mottin, Georgia Koutrika, Emmanuel Müller, Panagiotis Karras:
Figuring out the User in a Few Steps: Bayesian Multifidelity Active Search with Cokriging.
Proc. 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2019) [Full Text PDF] -
Tara Safavi, Caleb Belth, Lukas Faber, Davide Mottin, Emmanuel Müller, Danai Koutra:
Personalized Knowledge Graph Summarization: From the Cloud to Your Pocket
Proc. IEEE International Conference on Data Mining (ICDM 2019) [Full Text PDF] -
Anton Tsitsulin, Davide Mottin, Panagiotis Karras, Alex Bronstein, Emmanuel Müller:
NetLSD: Hearing the Shape of a Graph
Proc. 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2018) [Full Text PDF] -
Lukas Ruff, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Robert Vandermeulen, Alexander Binder, Emmanuel Müller, Marius Kloft:
Deep One-Class Classification
Proc. 35th International Conference on Machine Learning (ICML 2018) [Full Text PDF] -
Erik Scharwächter, Fabian Geier, Lukas Faber, Emmanuel Müller:
Low redundancy estimation of correlation matrices for time series using triangular bounds
Proc. 22nd Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2018) [Full Text PDF] -
Anton Tsitsulin, Davide Mottin, Panagiotis Karras, Emmanuel Müller:
VERSE: Versatile Graph Embeddings from Similarity Measures
Proc. 27th International Conference on World Wide Web (WWW 2018) [Full Text PDF] -
Arvind Shekar Kumar, Tom Bocklisch, Patricia Iglesias Sanchez, Christoph Strähle, Emmanuel Müller:
Multi-Feature Interactions and Redundancy for Feature Ranking in Mixed Data.
Proc. European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD 2017) [Full Text PDF] -
Davide Mottin and Emmanuel Müller:
Graph Exploration: From Users to Large Graphs
Proc. ACM International Conference on Management of Data (SIGMOD 2017) [Full Text PDF] -
Erik Scharwächter, Emmanuel Müller, Jonathan Donges, Marwan Hassani, Thomas Seidl:
Detecting Change Processes in Dynamic Networks by Frequent Graph Evolution Rule Mining
Proc. IEEE International Conference on Data Mining (ICDM 2016) [Full Text PDF] -
Fabian Keller, Emmanuel Müller, Klemens Böhm:
Estimating mutual information on data streams.
(Best Paper Award) Proc. 27th International Conference on Scientific and Statistical Database Management (SSDBM 2015) [Full Text PDF] -
Thibault Sellam, Emmanuel Müller, Martin L. Kersten:
Semi-Automated Exploration of Data Warehouses.
Proc. 24th ACM Conference on Information and Knowledge Management (CIKM 2015) [Full Text PDF] -
Bryan Perozzi, Leman Akoglu, Patricia Iglesias Sánchez, Emmanuel Müller:
Focused clustering and outlier detection in large attributed graphs.
Proc. 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2014) [Full Text PDF] -
Hoang Vu Nguyen, Emmanuel Müller, Klemens Böhm:
A Near-Linear Time Subspace Search Scheme for Unsupervised Selection of Correlated Features.
In Big Data Research Journal (1) 2014 [Full Text PDF] -
Hoang Vu Nguyen, Emmanuel Müller, Jilles Vreeken, Pavel Efros, Klemens Böhm:
Multivariate Maximal Correlation Analysis
Proc. 31th International Conference on Machine Learning (ICML 2014) [Full Text PDF] -
Patricia Iglesias Sánchez, Emmanuel Müller, Fabian Laforet, Fabian Keller, Klemens Böhm:
Statistical Selection of Congruent Subspaces for Mining Attributed Graphs.
Proc. IEEE International Conference on Data Mining (ICDM 2013) [Full Text PDF] -
Fabian Keller, Emmanuel Müller, Klemens Böhm:
HiCS: High Contrast Subspaces for Density-Based Outlier Ranking.
Proc. IEEE 28th International Conference on Data Engineering (ICDE 2012) [Full Text PDF] -
Emmanuel Müller, Matthias Schiffer, Thomas Seidl:
Statistical selection of relevant subspace projections for outlier ranking.
Proc. IEEE 27th International Conference on Data Engineering (ICDE 2011) [Full Text PDF] -
Emmanuel Müller, Stephan Günnemann, Ira Assent, Thomas Seidl:
Evaluating Clustering in Subspace Projections of High Dimensional Data.
Proc. 35th International Conference on Very Large Data Bases (VLDB 2009) [Full Text PDF]